Top Data Pipeline Architecture Examples to Boost Your Business
#data-pipeline-architecture-examples#data-engineering#cloud-architecture#elt-vs-etl#data-mesh
Choosing the right data pipeline architecture is a critical engineering decision, directly impacting scalability, cost, and time-to-insight. A poorly chosen model creates bottlenecks, inflates cloud bills, and leaves valuable data inaccessible. A well-designed architecture, however, becomes a strategic asset that empowers real-time analytics, machine learning, and data-driven business decisions.
This guide moves beyond theory to dissect 8 proven data pipeline architecture examples. Instead of generic overviews, we will provide a strategic breakdown of each pattern, from classic ETL to modern Data Mesh.
You will learn about the specific tech stacks, the trade-offs involved, and the key design decisions behind each model. We will explore the "why" behind their construction, offering replicable strategies and actionable takeaways. Our goal is to equip you with the insights needed to select and design a high-performance data pipeline that perfectly aligns with your specific use case, technical constraints, and business objectives. We will analyze the following architectures:
- Lambda and Kappa Architectures
- ETL (Extract, Transform, Load) vs. ELT (Extract, Load, Transform)
- Microservices-Based and Serverless Pipelines
- Data Mesh and Medallion Architectures
1. Lambda Architecture
Lambda Architecture is a robust data processing design pattern created to manage massive datasets by leveraging both batch and stream-processing methods. This dual-approach system provides a comprehensive and accurate view of data by combining historical analysis with real-time insights, making it a powerful example of a hybrid data pipeline architecture. The architecture is split into three distinct layers: the batch layer, the speed layer, and the serving layer.
How It Works: The Three Layers
The core strength of this architecture lies in its layered approach. The batch layer manages a master dataset, which is an immutable, append-only set of raw data. It pre-computes "batch views" from this entire dataset, ensuring comprehensive accuracy. Simultaneously, the speed layer processes data streams in real-time, compensating for the high latency of the batch layer by generating "real-time views" for the most recent data.
Finally, the serving layer indexes both the batch and real-time views. When a query is initiated, the serving layer merges results from both views to provide a complete and up-to-date answer. This ensures that users get low-latency responses for recent events while retaining access to highly accurate historical computations.
The following infographic illustrates the flow of data through the three distinct layers of the Lambda Architecture.
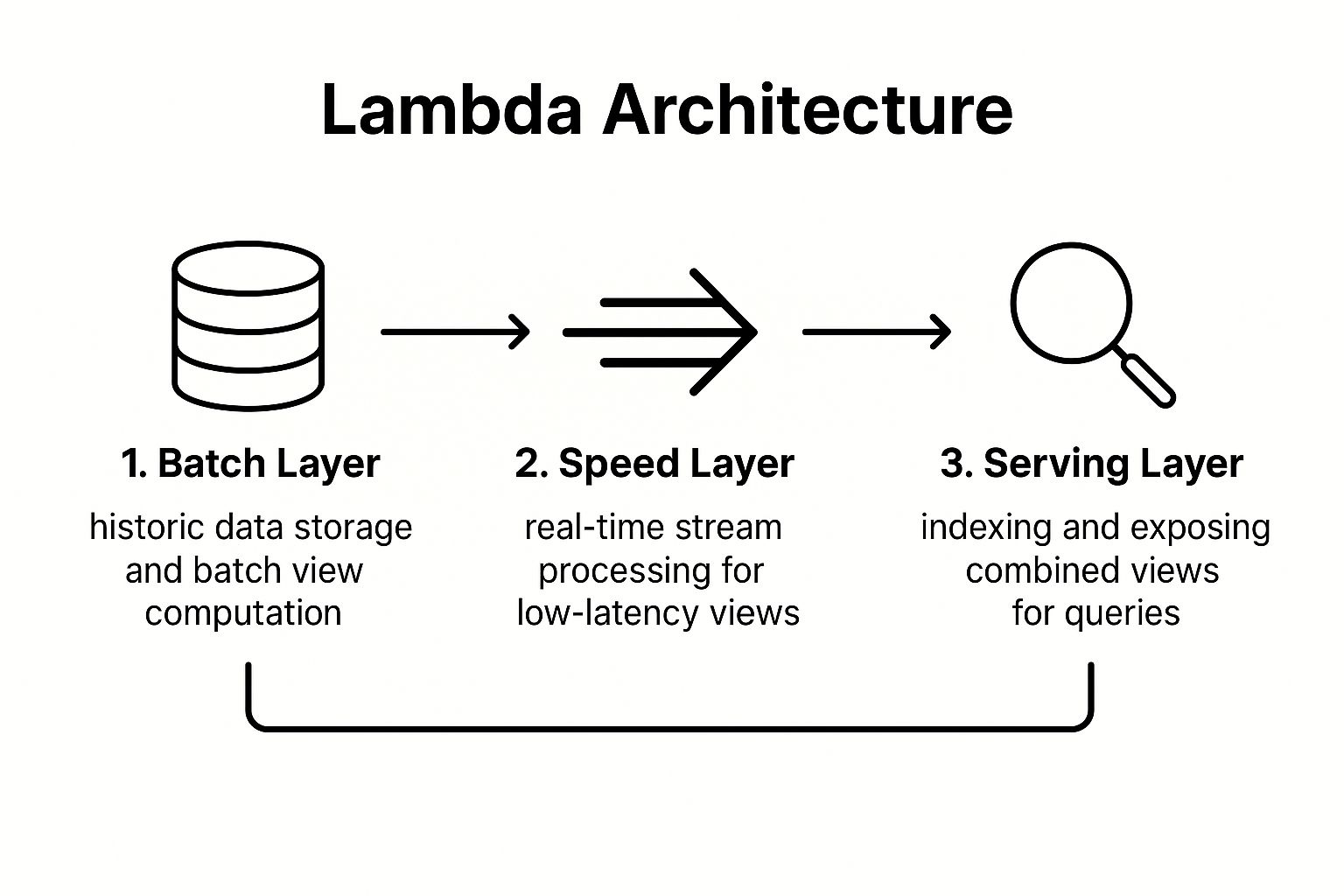
This process flow highlights how the architecture separates historical and real-time data processing before unifying them at the query stage.
Why It's a Top Example
Lambda Architecture deserves its place as a foundational data pipeline architecture example because it elegantly solves the problem of providing both real-time and historical data analysis without sacrificing accuracy or speed. It's highly fault-tolerant, as the immutable master dataset in the batch layer can always be used to regenerate views if errors occur.
Strategic Takeaways
- Use Case: Ideal for systems requiring low-latency queries on real-time data alongside complex analysis of large historical datasets, such as fraud detection, real-time personalization, and social media trend analysis.
- Tech Stack: A common implementation involves Apache Hadoop (HDFS) for the batch layer, Apache Storm or Flink for the speed layer, and a database like Cassandra for the serving layer.
- Key Insight: The main challenge is managing complexity and potential code duplication between the batch and speed layers. Frameworks like Apache Spark, which support both processing modes, can mitigate this. Plan for data reconciliation to ensure consistency between the layers.
2. Kappa Architecture
Kappa Architecture offers a simplified alternative to its Lambda counterpart, streamlining data processing by relying exclusively on a stream-based approach. This design pattern eliminates the batch layer entirely, treating all data as an immutable event stream. By using a single codebase and technology stack for both real-time and historical computations, it stands out as an elegant and efficient data pipeline architecture example.
This architecture's foundation is a durable, append-only log, where historical data analysis is performed by simply replaying the stream from the beginning. This single-path processing flow significantly reduces operational complexity and maintenance overhead compared to dual-path systems.
The following infographic illustrates the streamlined, single-path flow of data in the Kappa Architecture.
This diagram shows how all data, regardless of its age, is processed through a single stream processing engine.
Why It's a Top Example
Kappa Architecture is a top example because it addresses the primary drawback of the Lambda model: complexity. By unifying the processing logic, organizations can build and scale their data systems more efficiently. This approach is highly effective in scenarios where the same analytical logic applies to both real-time events and historical data, making it a powerful choice for modern, event-driven applications like those at LinkedIn and Uber.
Strategic Takeaways
- Use Case: Best suited for real-time analytics, IoT data processing, and event-sourcing systems where operational simplicity is a priority. It excels in applications like real-time user activity tracking, fraud detection, and dynamic pricing.
- Tech Stack: A typical stack includes Apache Kafka for the durable event log and a stream processing engine like Apache Flink, Apache Spark Streaming, or Apache Samza.
- Key Insight: Success hinges on your stream processing platform's ability to handle high-throughput replays efficiently. Ensure proper data retention policies are in place for the event log and design your data streams to be deterministic to guarantee consistent results upon reprocessing.
3. ETL (Extract, Transform, Load) Pipeline
ETL (Extract, Transform, Load) is a traditional and highly influential data pipeline architecture that has served as the backbone of business intelligence for decades. This process involves extracting data from various source systems, transforming it in a dedicated staging area, and then loading the refined data into a target data warehouse. The key characteristic of ETL is that the transformation happens before the load, ensuring data is structured, clean, and compliant with the target schema upon arrival.
How It Works: The Three Stages
The ETL process operates in a sequential, batch-oriented manner. First, the Extract phase pulls raw data from multiple sources like transactional databases, CRM systems, and flat files. Next, in the Transform stage, this data is moved to a staging area where it undergoes crucial changes. These transformations can include cleaning, validation, aggregation, and enrichment to conform to business rules and the target system's requirements.
Finally, the Load stage moves the fully transformed data from the staging area into its final destination, typically a data warehouse or data mart. This loaded data is optimized for analysis and reporting, providing a single source of truth for business decision-making. This structured approach is especially effective for integrating structured data and performing complex computations offline.
Why It's a Top Example
ETL stands out as one of the most fundamental data pipeline architecture examples because of its reliability and precision. It guarantees high-quality, standardized data in the target warehouse, which is essential for accurate business reporting and analytics. Its batch-processing nature makes it highly efficient for handling large, periodic data updates, such as end-of-day sales reporting or monthly financial consolidations.
For decades, enterprises like major banks have relied on ETL for regulatory reporting, and retail giants have used it to manage inventory and sales data. This long history has produced a mature ecosystem of robust tools and established best practices, making it a dependable choice for many core business functions.
Strategic Takeaways
- Use Case: Best suited for traditional business intelligence, data warehousing, and regulatory reporting where data quality, consistency, and complex transformations are more critical than real-time speed. Ideal for scenarios with predictable, batch-based data integration needs.
- Tech Stack: Classic ETL implementations often involve tools like Informatica PowerCenter, IBM DataStage, and Microsoft SSIS. Modern open-source alternatives include Talend and Apache NiFi.
- Key Insight: The primary challenge is its rigidity and latency; it's not designed for real-time data. To optimize performance, implement incremental loading for large datasets, schedule jobs during off-peak hours, and thoroughly document all transformation logic for long-term maintenance.
4. ELT (Extract, Load, Transform) Pipeline
The ELT (Extract, Load, Transform) Pipeline is a modern data integration architecture that inverts the traditional ETL process. Instead of transforming data before loading it, ELT extracts raw data from various sources and loads it directly into a target system, such as a cloud data warehouse or data lake. The transformation logic is applied after the data is loaded, leveraging the powerful computational resources of modern data platforms.
How It Works: The Three Stages
The ELT process streamlines data ingestion by deferring complex transformations. First, the Extract stage pulls raw data from sources like SaaS applications, databases, and logs. Next, the Load stage deposits this raw, unstructured data directly into a high-performance storage and processing environment like Snowflake or BigQuery.
Finally, the Transform stage occurs within the data warehouse itself. Analysts and engineers use SQL or other tools like dbt to clean, model, and enrich the raw data, creating production-ready datasets for analytics and business intelligence. This approach offers immense flexibility, as the raw data is always available for re-transformation as business needs evolve.
Why It's a Top Example
ELT stands out as a leading data pipeline architecture example because it is purpose-built for the scalability and power of the cloud. By leveraging the target system's processing capabilities, it eliminates the need for a separate, often costly, transformation engine. This "schema-on-read" approach accelerates data availability, allowing teams to start exploring raw data immediately without waiting for lengthy transformation jobs to complete. Companies like Spotify and Lyft use ELT to rapidly load massive datasets into systems like Google BigQuery and Snowflake for timely analysis.
Strategic Takeaways
- Use Case: Perfect for organizations with cloud data warehouses that need to analyze large, diverse datasets with high speed and flexibility. It is ideal for data exploration, business intelligence, and machine learning model training where access to raw data is crucial.
- Tech Stack: Popular tools include Fivetran or Stitch for extraction and loading, Snowflake, Google BigQuery, or Amazon Redshift as the target warehouse, and dbt (data build tool) for managing SQL-based transformations.
- Key Insight: The primary advantage is flexibility, but this can introduce complexity. Without strong governance, the data lake can become a "data swamp." Implement robust data cataloging and use tools like dbt for version-controlled, documented transformations to maintain order and reliability.
5. Microservices-Based Data Pipeline
A Microservices-Based Data Pipeline decomposes data processing into a collection of small, independent, and loosely-coupled services. Each microservice is responsible for a single, specific task within the pipeline, such as ingestion, validation, or transformation. This modular approach brings the agility and scalability of microservices architecture directly into the world of data engineering, allowing teams to build and maintain complex systems with greater flexibility.
How It Works: The Modular Approach
Instead of a single, monolithic application handling all data processing, this architecture uses a series of specialized services that communicate through APIs or message queues. For example, one service might ingest data from a source, another might validate its schema, a third could enrich it with external data, and a final one might load it into a data warehouse. Each service can be developed, deployed, and scaled independently of the others.
This separation of concerns allows different teams to own different parts of the data pipeline. It also enables the use of the best technology for each specific job. This model is a prime example of a distributed data pipeline architecture, promoting autonomy and resilience.
Why It's a Top Example
The Microservices-Based Data Pipeline is a top example because it directly addresses the scalability and maintenance challenges of monolithic data systems. By breaking down the pipeline, it enables parallel development, independent deployments, and targeted scaling. Companies like Netflix and Uber leverage this pattern extensively to manage their massive data streams, allowing them to innovate faster and respond to failures with surgical precision.
Strategic Takeaways
- Use Case: Ideal for large-scale, complex data platforms in organizations with multiple engineering teams. It excels in scenarios requiring high availability, independent component scaling, and diverse technology stacks, such as real-time analytics platforms and event-driven data processing systems.
- Tech Stack: Common technologies include Docker and Kubernetes for containerization and orchestration, Apache Kafka or RabbitMQ for asynchronous communication, and API Gateways like Kong for managing service interactions.
- Key Insight: The primary challenge is managing the complexity of a distributed system. Establish clear data contracts between services to prevent integration issues. Implementing robust monitoring, distributed tracing, and fault tolerance patterns like circuit breakers is not optional; it's essential for operational stability.
6. Data Mesh Architecture
Data Mesh is a decentralized, socio-technical data architecture approach that treats data as a product. Pioneered by Zhamak Dehghani, it shifts ownership of analytical data from a central team to the individual business domains that produce it. This model organizes data around specific business domains, such as marketing or sales, with each domain team responsible for managing and sharing its data products. The architecture is built on four core principles: domain-oriented decentralized data ownership, data as a product, self-serve data infrastructure, and federated computational governance.
How It Works: The Four Principles
The Data Mesh model fundamentally reorganizes how organizations handle data at scale. Instead of funneling all data into a central lake or warehouse, each domain team owns its own analytical data pipeline. They are responsible for cleaning, transforming, and serving their data as high-quality, discoverable "data products" that other teams can consume.
This decentralized ownership is supported by a central platform team that provides self-serve infrastructure and tools, empowering domain teams to build and manage their data products independently. A federated governance body sets global standards for interoperability, security, and quality, ensuring consistency across the organization without creating a centralized bottleneck. This approach makes data more accessible, reliable, and aligned with business needs.
Why It's a Top Example
Data Mesh is a transformative data pipeline architecture example because it directly addresses the scalability and ownership bottlenecks of traditional, centralized systems. By distributing data responsibility, it fosters a culture of data ownership and accountability, leading to higher-quality data products. Its decentralized nature allows organizations like Zalando and Intuit to innovate faster, as domain teams can operate autonomously without waiting on a central data team.
Strategic Takeaways
- Use Case: Best suited for large, complex organizations with multiple business domains where a centralized data team becomes a bottleneck. It excels in environments aiming to empower domain experts and scale data initiatives rapidly.
- Tech Stack: Technology is flexible but often includes a data catalog (like Alation or Collibra) for discovery, stream-processing tools (like Kafka), and cloud-native storage (like S3 or GCS) managed via a self-serve platform.
- Key Insight: Success depends as much on organizational change as it does on technology. Start with a pilot domain to prove the model's value and invest heavily in creating robust self-serve infrastructure and clear governance standards before expanding across the enterprise.
7. Serverless Data Pipeline
Serverless Data Pipeline architecture represents a paradigm shift in data processing, leveraging cloud services that abstract away all underlying infrastructure management. This approach allows developers to build and run applications without provisioning or managing servers. Instead, the cloud provider automatically handles scaling, patching, and operations, enabling teams to focus purely on code and business logic. The architecture is built on event-driven, ephemeral compute functions like AWS Lambda or Azure Functions.
How It Works: Event-Driven Execution
In a serverless model, data processing is triggered by specific events. These triggers could be a new file landing in a storage bucket (like Amazon S3), a message arriving in a queue, a database update, or a direct API call. When an event occurs, it invokes a small, single-purpose function that executes a specific task, such as transforming data, enriching a record, or loading it into a data warehouse.
This design breaks down a complex pipeline into a series of independent, stateless functions. These functions can be orchestrated using services like AWS Step Functions to create sophisticated workflows. Since you only pay for the compute time you consume, this architecture is exceptionally cost-effective for workloads with variable or unpredictable traffic patterns.
Why It's a Top Example
The serverless model is a leading data pipeline architecture example because it offers unparalleled agility, scalability, and operational efficiency. It dramatically reduces the time to market for new data products by eliminating infrastructure overhead. Companies like Netflix leverage this approach for media processing, while iRobot processes IoT data from millions of devices, showcasing its power to handle massive, event-driven workloads without a dedicated operations team.
This architecture's pay-per-use pricing model also makes it financially attractive, especially for startups and projects with fluctuating demand. The inherent auto-scaling capabilities ensure the pipeline can handle sudden spikes in data volume seamlessly, providing a level of resilience and flexibility that is difficult to achieve with traditional server-based architectures.
Strategic Takeaways
- Use Case: Perfect for event-driven processing like real-time IoT data ingestion, image and video processing automation, log analysis, and data transformation tasks that run intermittently. It excels where workloads are unpredictable or sporadic.
- Tech Stack: Common components include AWS Lambda, Azure Functions, or Google Cloud Functions for compute, Amazon S3 or Azure Blob Storage for storage, Amazon SQS or Kinesis for queuing, and AWS Step Functions for orchestration.
- Key Insight: Success in serverless design hinges on creating stateless, idempotent functions. Monitor for "cold starts" (the latency of invoking a function for the first time) and optimize function memory and timeout settings to balance performance and cost.
8. Medallion Architecture (Bronze/Silver/Gold)
Medallion Architecture is a modern data design pattern that organizes data within a data lakehouse into three distinct quality layers: Bronze, Silver, and Gold. This tiered approach incrementally improves the structure and quality of data, ensuring reliability and usability for analytics. The architecture provides a logical progression from raw, ingested data to highly refined, business-ready insights, making it a foundational example of a structured data pipeline architecture.
The following infographic illustrates the flow of data through the three distinct layers of the Medallion Architecture.
How It Works: The Three Layers
The core of this architecture lies in its structured data refinement process. The Bronze layer serves as the initial landing zone, containing raw, immutable data ingested directly from source systems. This layer prioritizes preserving the original state of the data, providing a historical archive for reprocessing if needed.
Next, the Silver layer takes data from the Bronze layer and applies cleaning, validation, and enrichment. Data is standardized, conformed, and often joined to create a more reliable and queryable "single source of truth." Finally, the Gold layer contains highly aggregated and refined data, optimized for specific business intelligence and analytics use cases. These tables are typically organized by business subject area and are ready for consumption by downstream applications.
Why It's a Top Example
Medallion Architecture is a top example because it provides a clear, scalable framework for building reliable and high-quality data pipelines in a lakehouse environment. It decouples raw data ingestion from business-level aggregation, improving maintainability and data governance. This layered approach also enhances data quality by enforcing validation checks at each stage, giving data consumers confidence in the final output. Companies like Shell and H&M leverage this pattern to manage massive datasets for IoT and retail analytics.
Strategic Takeaways
- Use Case: Ideal for organizations building a data lakehouse that requires strong data quality guarantees, data lineage tracking, and support for diverse analytics workloads from data science to business intelligence.
- Tech Stack: Commonly implemented using Databricks with Delta Lake, which provides ACID transactions to the data lake, alongside Apache Spark for data processing.
- Key Insight: The main challenge is defining the right transformations between layers. Keep the Bronze-to-Silver logic focused on cleansing and conformance, while Silver-to-Gold logic should handle business-specific aggregations. This separation prevents complexity and ensures each layer serves its intended purpose.
Data Pipeline Architecture: 8-Model Comparison
| Architecture | Implementation Complexity | Resource Requirements | Expected Outcomes | Ideal Use Cases | Key Advantages |
|---|---|---|---|---|---|
| Lambda Architecture | High - multiple layers and codebases | High - batch and speed layer infra | Balanced latency and throughput, fault-tolerant, accurate data | Real-time analytics with historical context, fraud detection, IoT | Combines batch & real-time, high fault tolerance, scalable |
| Kappa Architecture | Moderate - single stream processing codebase | Moderate - robust streaming infra | Unified stream processing for real-time and historical data | Real-time analytics, event-driven apps, continuous pipelines | Simplified architecture, single codebase, easier maintenance |
| ETL Pipeline | Moderate - traditional batch jobs | Moderate - ETL tooling and staging | Clean, validated, structured data loaded for analysis | Data warehousing, BI reporting, regulatory compliance | Mature tooling, reliable data quality, optimized transformations |
| ELT Pipeline | Moderate - leverages cloud power | High - requires powerful target compute | Raw data stored with flexible transformations in target | Cloud data lakes/warehouses, self-service analytics | Faster loading, flexible schema-on-read, raw data preservation |
| Microservices-Based Pipeline | High - multiple independent services | High - service orchestration & infra | Highly scalable, modular data processing with team autonomy | Distributed processing, event-driven data, multi-team orgs | Scalability, fault isolation, parallel development |
| Data Mesh Architecture | High - cultural and technical shift | High - self-serve infra and governance | Decentralized data ownership with domain-aligned products | Large enterprises, multi-domain organizations | Domain data ownership, improved data quality & agility |
| Serverless Data Pipeline | Low to moderate - depends on provider | Low to moderate - cloud managed resources | Event-driven, scalable pipelines with pay-per-use cost model | Event-driven processing, IoT ingestion, variable workloads | Reduced ops overhead, automatic scaling, cost-efficient |
| Medallion Architecture | Moderate - layered data refinement | Moderate - storage for multiple data copies | Clear data quality progression and lineage | Lakehouse implementations, regulated industries | Incremental processing, data governance, clear data layers |
Choosing Your Blueprint: From Examples to Execution
As we've explored, the world of data engineering offers no single "perfect" data pipeline architecture. The examples in this guide, from the classic batch-oriented ETL to the decentralized Data Mesh, demonstrate that the optimal choice is a direct reflection of your specific business context, data maturity, and strategic objectives. The right blueprint isn't just about adopting the latest trend; it's about making a calculated decision based on your unique operational realities.
The core lesson is to move beyond simply copying a template. Instead, focus on the underlying principles each architecture champions. Lambda teaches us to balance historical accuracy with real-time needs, while Kappa pushes for simplicity through a unified streaming approach. The modern ELT pattern highlights the power of cloud data warehouses, and the Medallion architecture provides a clear roadmap for progressive data refinement and governance.
Synthesizing the Key Takeaways
To translate these data pipeline architecture examples into a working strategy, distill your analysis into a few critical decision points. Don't get lost in the technical weeds before you've clarified the fundamental requirements of your project.
Start by evaluating these core factors:
- Latency vs. Cost: Do you need sub-second insights (favoring Kappa or Serverless), or can you operate efficiently with daily batch updates (making traditional ETL/ELT viable)? Real-time processing often carries a higher operational cost and complexity.
- Scale and Complexity: Are you building a system for a single team, or are you designing an enterprise-wide solution for dozens of domains? A simple ELT pipeline might be perfect for the former, whereas a Data Mesh is built to handle the organizational complexity of the latter.
- Team Structure and Skills: Your team's expertise is a critical constraint. A small team may thrive with a managed, serverless pipeline, while a microservices-based architecture demands a strong DevOps culture and specialized engineering skills.
- Data Governance and Quality: For organizations in regulated industries or those aiming for a single source of truth, the structured, multi-layered approach of a Medallion architecture offers built-in quality gates that a simpler pipeline might lack.
Your Actionable Next Steps
Armed with these insights, your path forward involves deliberate action. The goal is to build a robust data foundation that not only solves today's problems but is also flexible enough to adapt to tomorrow's challenges.
- Document Your Use Cases: Clearly define the top 3-5 business problems your data pipeline needs to solve. Assign specific metrics for success, such as "reduce report generation time by 50%" or "enable real-time fraud detection."
- Score the Architectures: Create a simple matrix to score each architecture (ETL, ELT, Kappa, etc.) against your key requirements (latency, cost, team skills, governance). This objective exercise will help surface the most logical candidates.
- Prototype a Core Workflow: Select the most promising architecture and build a small-scale proof of concept (POC). Process a single data source from ingestion to a dashboard to validate your assumptions and identify unforeseen technical hurdles.
Ultimately, mastering these data pipeline architecture examples is about more than just moving data; it's about building the circulatory system for a data-driven organization. The right architecture empowers teams, accelerates innovation, and transforms raw information into a decisive competitive advantage. Choose wisely, build incrementally, and stay focused on the business value you aim to deliver.
Navigating the complexities of these architectural patterns requires deep expertise. If you're looking to design and implement a custom, cloud-native data solution that drives measurable results, the team at Pratt Solutions can help. We specialize in turning complex data challenges into strategic assets, from architecting scalable ELT pipelines to deploying automated, AI-driven infrastructure. Visit Pratt Solutions to see how we can build your data-driven future.